Reinforcement learning
Contents
12.1. Reinforcement learning#
So far, we’ve talked of machines learning in the form of pattern recognition. We provide data to the computer and ask it to tell us either how inputs and outputs fit together according to some set of rules (e.g., linear regression, \(k\)-NN), or we ask it to tell us something about the underlying structure of the data based on the location of our observations in the feature space.
In reinforcement learning, we take a new approach to what it means to “learn”. Rather than asking the computer to memorize and apply patterns, we give the computer inputs, such as the rules of a particular game and some strategies by which to play it, and our algorithm will be rewarded or punished based on how those strategies do as they’re implemented in a trial and error fashion.
Really, the transition from “learning” in the supervised sense, to unsupervised, and now to reinforcement learning maps our journey in learning data science in this book: we began by telling you what the code and basic statistical principals are and how they work, we started to explore how you might discover or determine which type of model might best suit our underlying data and question, and now you’re at a stage where you can start to go out of the nest and find out via trial and error how to address new data science problems as they come your way.
Overview of RL#
Reinforcement learning has been around since long before computers and machine learning were part of our lives. At its core, Reinforcement learning is
learning over time based on feedback (“reinforcements”) in order to achieve some goal.
Really, much of life is RL: whether we want to play the cello, cook a recipe, or learn data science, we might start with rote memorization, but in order to get anywhere meaningful, we usually need to try out different strategies – practicing every day rather than twice a week, setting the burner to medium-high rather than high, or working in longer, fewer bursts rather than a little bit every day – working out which strategies are most helpful for us to reach our goal of playing music, cooking, and doing data science – are all examples of implementing our own personal reinforcement learning algorithms.
In slightly more formal terms, when we are thinking about the world through an RL lens, we are creating a mathematical framework for defining what it means to behave optimally, i.e.,
maximizing cumulative rewards and minimizing losses in a changing, stochastic (i.e., random) world
Again, this should really remind you of your own life and your efforts to figure out, you know, what to do with it. (If it doesn’t, congratulations on having everything stunningly figured out.)
How do we figure out how to behave optimally? Here’s where the reinforcements come in. Reinforcements are signals about how you’re performing that you then use to change your behavior. In RL the signals are generally evaluative rather than corrective. That is, you get information about whether what you’re doing is earning you higher or lower rewards at any given moment, but you do not get information about the global “best” outcome, how close you are to it, or a convenient map about precisely how to get there. In fact, that may be entirely unknown not just by you, or your computer, but also by your teacher, coach, or programmer. In fact, one circumstance where RL can be most powerful is when we don’t actually know what strategy will work best, and so we set our computer to work trying out a whole bunch of them many times under changing circumstances and then we asses how each strategy did.
An analogy that might be helpful comes from Herbert Simon, a political scientist who also worked in computer science, economics, and cognitive psychology, among other fields, and won both the Nobel Prize in economics and the Turing Prize in computer science. He is credited with establishing many foundational ideas complexity, artificial intelligence, decision-making, and organizational evolution, among much more. In his 1969 book, The Sciences of the Artificial, Simon describes an ant walking on the beach. We, the observer, may notice the ant is moving in what appears to be a complex, winding pattern with much nuance. We might thus be tempted to observe that the ant is following a complicated strategy and perhaps is much smarter than we’ve given it credit. But really, it’s the terrain that’s complex (there are little hills due to the wind, rocks, perhaps tides coming in and out), and the ant is following very simple rules to get to where it’s going, such as something like: go up when there’s an incline, go around when something is in front of you.
This is one of the key ideas of RL: can we get computers to complete seemingly complex tasks and solve what appear to be quite difficult problems, by using relatively (often surprisingly) simple strategies? The answer, very excitingly, is often yes.
A brief(!) history#
As with much of what we’ve covered in this class, RL as we use it today in data science is a modern implementation of an idea that’s been around for some time. The credit for the initial idea is generally attributes to Ivan Pavlov and his famous dogs, where around the turn of the century from the 1800s to 1900s he discovered he could get dogs to salivate not just by bringing them food, but by conditioning them to respond to other cues associated with food, such as the steps of his lab assistants or the ringing of a bell.

Fig. 12.1 One of Pavlov’s famous (and probably hungry) salivating dogs#
If you’re more of a cat person, I have good news: RL also came up shortly after Pavlov in the form of Thorndike’s cats. Around the same time that Pavlov was ringing bells in front of dogs, Edward Thorndike was putting cats in complicated boxes that required a number of steps, such as pressing a lever or pulling a string, to get out. He discovered that once the cats figured out how to get out of a box once, the next times he put these cats back in the boxes, they were able to get out faster than the first time. He summarized this as his Law of Effect:
The more an action gives rise to positive consequences, the more likely it is to be repeated. The more it gives rise to negative consequences, the less likely it is to be repeated.
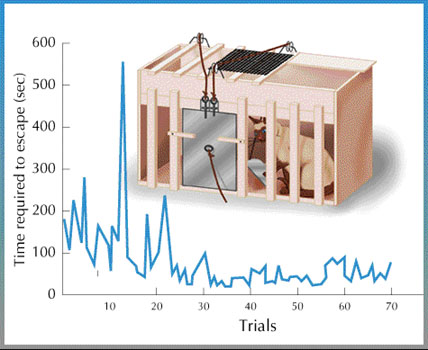
Fig. 12.2 One of Thorndike’s hopefully not claustrophobic cats#
We’ll pick up the pace in our history now, and zoom to another big point of inflection in RL, which is when Alan Turing, a British computer scientist, cryptologist, mathematician, philosopher, and theoretical biologist, for whom the Turing Prize is named, and who is credited with, among many achievements, crucial codebreaking in World War II on behalf of the Allies against Germany and the Axis powers, as well as inventing an early version of a modern-day computer and algorithm, the Turing Machine.
Many books and movies have been written and made about Alan Turing, as not only are his contributions to our present-day world impossible to overstate, but he also was treated horribly and tragically by the British government for homosexuality, which led to his untimely death of disputed causes in 1954. Today, in Britain a law implemented in 2017 that pardons people who were punished for homosexuality is known as the “Alan Turing Law.”
(Among many lessons and heartbreaking details from this story are some that preview our ethics chapter to come: progress in science is not guaranteed, and our own ideas about not just what counts as good, intereting, or important research, but also who gets to do that science (and live their life), can absolutely get in the way of important discoveries, never mind people’s lives.)
Back to RL: We owe much to Alan Turing in data science, and you’ll surely meet him again as you continue, for his contributions are widespread, far-reaching, and immense. For now, we focus on this passage in his 1948 paper, “Intelligent Machinery: A Heretical Theory”. He writes:
“My contention is that machines can be constructed which will simulate the behaviour of the human mind very closely. They will make mistakes at times, and at times they may make new and very interesting statements, and on the whole the output of them will be worth attention to the same sort of extent as the output of a human mind.”
Then later:
“When a configuration is reached for which the action is undetermined, a random choice for the missing data is made and the appropriate entry is made in the description, tentatively, and is applied. When a pain stimulus occurs all tentative entries are cancelled, and when a pleasure stimulus occurs they are all made permanent.”
Here, he’s creating a powerful connection between earlier research on how animals learn to the possibility of an intelligent computer. This moment of connection between previously disparate fields effectively marked the beginning of much fruitful research in artificial intelligence and reinforcement learning.
Today, this idea – not just that machines can learn from data, but that they can explore and discover new ways of learning is behind some of the most impressive applications of AI and RL, including AlphaGo, the first computer program to defeat a human expert in the (very) complicated game of Go.
Further reading#
From here, we are going to jump right into building some intuition for using RL ourselves by exploring the classic \(k\)-armed bandit problem (side note: data scientists love the letter \(k\), don’t we?!). If you’re interested in reading more about RL more generally, including its history, as well as more advanced applications, the (as of writing this textbook) free, online book Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto, is a good place to start.